
Multi-view Convolutional Neural Networks
for 3D Shape Recognition
People
Updates
- A PyTorch implementation from our lab with a new shading style.
- A sample Caffe implementation is now available in additional to the Matlab version. Thanks Haibin Huang for the contribution!
Abstract
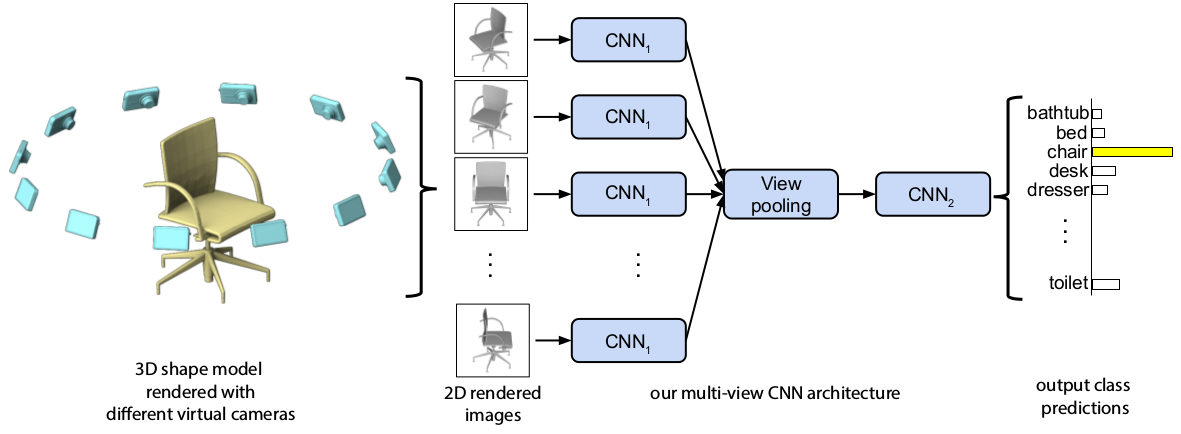
A longstanding question in computer vision concerns the representation of 3D shapes for recognition: should 3D shapes be represented with descriptors operating on their native 3D formats, such as voxel grid or polygon mesh, or can they be effectively represented with view-based descriptors? We address this question in the context of learning to recognize 3D shapes from a collection of their rendered views on 2D images. We first present a standard CNN architecture trained to recognize the shapes’ rendered views independently of each other, and show that a 3D shape can be recognized even from a single view at an accuracy far higher than using state-of-the-art 3D shape descriptors. Recognition rates further increase when multiple views of the shapes are provided. In addition, we present a novel CNN architecture that combines information from multiple views of a 3D shape into a single and compact shape descriptor offering even better recognition performance. The same architecture can be applied to accurately recognize human hand-drawn sketches of shapes. We conclude that a collection of 2D views can be highly informative for 3D shape recognition and is amenable to emerging CNN architectures and their derivatives.
Papers
Hang Su, Subhransu Maji, Evangelos Kalogerakis, Erik Learned-Miller, "Multi-view Convolutional Neural Networks for 3D Shape Recognition",
Proceedings of ICCV 2015 [pdf] [arxiv] [bibtex] [data] [code] [video](6M)
M. Savva, F. Yu, H. Su, M. Aono, B. Chen, D. Cohen-Or, W. Deng, H. Su, S. Bai, X. Bai, N. Fish, J. Han, E. Kalogerakis, E. G. Learned-Miller, Y. Li, M. Liao, S. Maji, A. Tatsuma, Y. Wang, N. Zhang, and Z. Zhou, "SHREC’16 Track: Large-Scale 3D Shape Retrieval from ShapeNet Core55",
Eurographics Workshop on 3D Object Retrieval, J. Jorge and M. Lin, editors, 2016 [pdf] [SHREC'16 contest]
Extras
reorientmeshfaces.7z: Code used to re-orient the faces of the ModelNet database meshes such that the surface normals point outwards i.e., are directed away from the shape interior. The code uses ray casting to find the direction of largest visibility per triangle and might be slow for large meshes.